Objects¶
-
class
Instance¶
-
class
Surface¶
Surface.image.Instance.present() is called.-
class
Task¶
-
class
Framebuffer¶
-
class
RenderPipeline¶
Task.run() is called.-
class
ComputePipeline¶
Task.run() is called.-
class
Group¶
__exit__ the command buffer is executed and the output memory views are filled with data.-
class
Buffer¶
-
class
Image¶
-
class
Memory¶
Documentation¶
Instance objects¶
-
glnext.instance(physical_device: int = 0, application_name: str = None, application_version: int = 0, engine_name: str = None, engine_version: int = 0, backend: str = None, surface: bool = False, layers: list = None, cache: bytes = None, debug: bool = False) → Instance¶
-
Instance.surface(window: tuple, image: Image) → Surface¶ - Parameters
window (tuple) – The window handle in the (hinstance, hwnd) format for windows and (display, window) format for linux.
image (Image) – The source image.
-
Instance.buffer(type: str, size: int, readable: bool = False, writable: bool = True, memory: Memory = None) → Buffer¶
-
Instance.image(size: tuple, format: str = '4p', levels: int = 1, layers: int = 1, mode: str = 'output', memory: Memory = None) → Image¶ - Parameters
format (str) – formats
-
Instance.group(buffer: int) → Group¶ - Parameters
buffer (int) – The staging buffer size. The staging buffer must large enough to support all the reads and writes within the buffer. The size of the staging buffer is usually the expected maximum number of transfered bytes within the group. The staging buffer consumes the host memory.
__exit__.More on this at How glnext groups work?
-
Instance.present()¶
More on this at How glnext present works?
-
Instance.cache() → bytes¶
cache=None.Instance with cache=data to enable the pipeline cache.Reasoning behind the cache parameter and the cache function:
There are two best practices to follow:
Have a single pipeline cache.
When having a pipeline cache the user is expected to provide its content when creating the instance.This can be done with the following code:my_pipeline_cache_data = b'' if os.path.exists('my_pipeline_cache.cache'): my_pipeline_cache_data = open('my_pipeline_cache.cache', 'rb').read() instance = glnext.instance(cache=my_pipeline_cache_data) # ... the program goes here open('my_pipeline_cache.cache', 'wb').write(instance.cache())
In this example the cache parameter is alwaysbyteseven on the first run.There are better ways to load and store binary data. This example is just a short working example.Have no caching at all.
To disable the pipeline cache entirely set the cache toNone.AnInstancecreated withcache=Nonewill not generate cache on pipeline creation and theInstance.cache()will fail with an error.
Surface objects¶
Surface.image attribute to a different image.Task objects¶
-
Task.framebuffer(size: tuple, format: str = '4p', samples: int = 4, levels: int = 1, layers: int = 1, depth: bool = True, compute: bool = False, mode: str = 'output', memory: Memory = None) → Framebuffer¶
-
Task.compute(compute_shader: bytes, compute_count: tuple, bindings: list, memory: Memory = None) → ComputePipeline¶
-
Task.run()¶
RenderPipeline and ComputePipeline objects derived from this objects.Framebuffer objects¶
-
Framebuffer.render(vertex_shader, fragment_shader, task_shader, mesh_shader, vertex_format, instance_format, vertex_count, instance_count, index_count, indirect_count, max_draw_count, vertex_buffer, instance_buffer, index_buffer, indirect_buffer, count_buffer, vertex_buffer_offset, instance_buffer_offset, index_buffer_offset, indirect_buffer_offset, count_buffer_offset, topology, restart_index, short_index, depth_test, depth_write, bindings, memory) → RenderPipeline¶
-
Framebuffer.compute(compute_shader: bytes, compute_count: tuple, bindings: list, memory: Memory = None) → ComputePipeline¶
-
Framebuffer.update(clear_values: bytes, clear_depth: float, **kwargs)¶
RenderPipeline objects¶
-
RenderPipeline.update(vertex_count: int, instance_count: int, index_count: int, indirect_count: int, **kwargs)¶
Group objects¶
group = instance.group(buffer=1024) # Create a group with a staging buffer of 1024 bytes
#
with group: # Begin Command Buffer
buffer1.write(data1) # Copy data 1 into the staging buffer
task1.run() # Copy task 1 into the command buffer
task2.run() # Copy task 2 into the command buffer
buffer2.read() # Copy buffer 2 into the staging buffer
# End Command Buffer
data2 = bytes(group.output[0]) # Copy from the staging buffer to a Python variable
-
Group.__enter__()¶
__exit__:-
Group.__exit__()¶
Memory objects¶
Diagrams¶
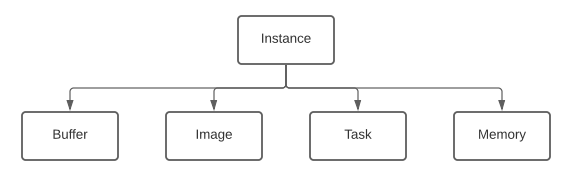
Object Hierarchy¶
On the diagram the [A] -> [B] represents “an instance of B can be created from an instance of A”.
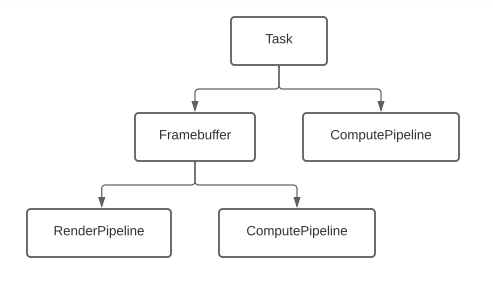
Task Execution¶

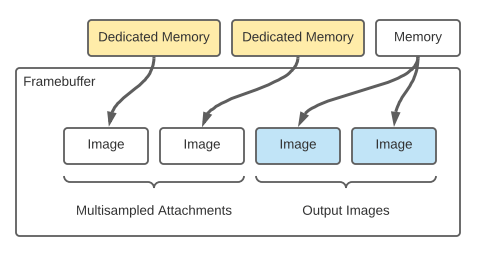
Framebuffer execution¶

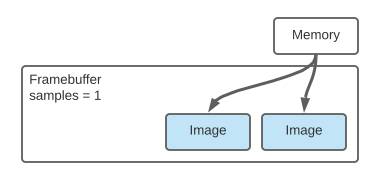
samples = 1.compute = True can have Compute Pipelines attached to it.
The Compute Pipelines of the Framebuffer are considered to be the postprocessing step.compute = True the output image will transition into shader storage optimal first.
After the Compute Pipelines execute the image is transitioned to respect the Framebuffer mode.Framebuffer Memory¶
Formats¶
Format |
Vulkan Format |
|---|---|
|
VK_FORMAT_R32_SFLOAT |
|
VK_FORMAT_R32G32_SFLOAT |
|
VK_FORMAT_R32G32B32_SFLOAT |
|
VK_FORMAT_R32G32B32A32_SFLOAT |
|
VK_FORMAT_R16_SFLOAT |
|
VK_FORMAT_R16G16_SFLOAT |
|
VK_FORMAT_R16G16B16_SFLOAT |
|
VK_FORMAT_R16G16B16A16_SFLOAT |
|
VK_FORMAT_R32_SINT |
|
VK_FORMAT_R32G32_SINT |
|
VK_FORMAT_R32G32B32_SINT |
|
VK_FORMAT_R32G32B32A32_SINT |
|
VK_FORMAT_R32_UINT |
|
VK_FORMAT_R32G32_UINT |
|
VK_FORMAT_R32G32B32_UINT |
|
VK_FORMAT_R32G32B32A32_UINT |
|
VK_FORMAT_R8_UINT |
|
VK_FORMAT_R8G8_UINT |
|
VK_FORMAT_R8G8B8_UINT |
|
VK_FORMAT_R8G8B8A8_UINT |
|
VK_FORMAT_R8_UNORM |
|
VK_FORMAT_R8G8_UNORM |
|
VK_FORMAT_R8G8B8_UNORM |
|
VK_FORMAT_R8G8B8A8_UNORM |
|
VK_FORMAT_R8_SRGB |
|
VK_FORMAT_R8G8_SRGB |
|
VK_FORMAT_R8G8B8_SRGB |
|
VK_FORMAT_R8G8B8A8_SRGB |
|
VK_FORMAT_UNDEFINED |
|
VK_FORMAT_UNDEFINED |
|
VK_FORMAT_UNDEFINED |
|
VK_FORMAT_UNDEFINED |
|
VK_FORMAT_UNDEFINED |
|
VK_FORMAT_UNDEFINED |
|
VK_FORMAT_UNDEFINED |
Image Formats¶
'4p' # 4 pixels
'4b' # 4 byes
'3f' # 3 floats
'4h' # 4 half floats
'3h' # 3 half floats, but it is unlikely to be supported (size = 6)
'3p' # 3 pixels, but it is unlikely to be supported (size = 3)
'2f 2f' # multiple attachments are not supported for images
'4x' # padding is not supported for images
Warning
Do not use Image formats with size not divisible by four. Those may be supported on you platform, but not on others.
Framebuffer Formats¶
'4p' # 4 pixels
'3f' # 3 floats
'4h 1f' # 4 half floats and one float
'3h 2b' # 3 half floats and 2 bytes, but it is unlikely to be supported (size = 6 + 2)
'2f 2f' # 2 floats and 2 floats
'2f 4x 2f' # padding is not supported for framebuffers
Note
Vertex Formats¶
'4b' # 4 bytes
'3f' # 3 floats
'3h 2b' # 3 half floats and 2 bytes
'2f 2f' # 2 floats and 2 floats
'2f 4x 2f' # 2 floats, 4 bytes padding and 2 floats
'2f 1b' # 2 floats and 1 byte
Matrix Vertex Input¶
#version 450
in layout (location = 0) in vec3 position;
in layout (location = 1) in mat3 rotation;
in layout (location = 4) in vec3 scale;
mat3 rotation consumes 3 attribute locations.3f 3f 3f.